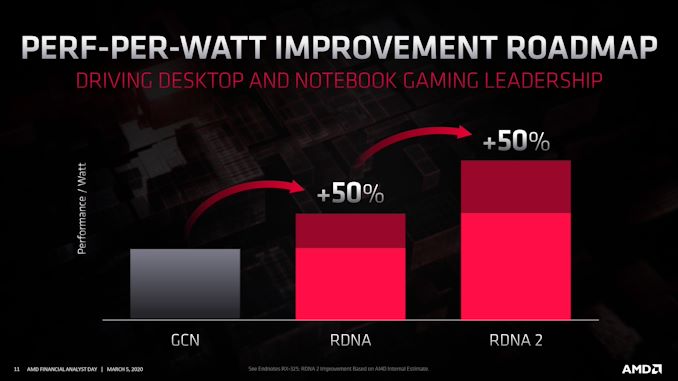
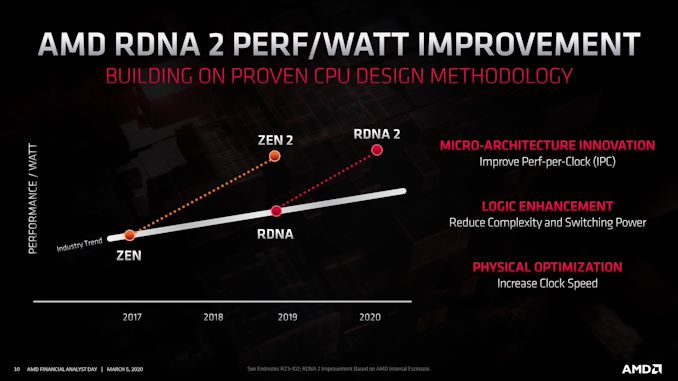
Acer Japan has unleashed the company’s first Predator displays that use Fast IPS panels, and therefore offering a 240 Hz refresh rate along with all the advantages that the IPS technology has, including rich colors, and wide viewing angles. The new 24.5-inch and 27-inch Acer Predator 240 Hz IPS LCDs also support VESA’s Adaptive-Sync technology and are Display HDR400-certified.
Acer’s lineup of Fast IPS monitors currently consists of two models: the 24.5-inch Predator XB253QGXbmiiprzx as well as the 27-inch Predator XB273GXbmiiprzx (not a typo). General characteristics of the displays are similar to those of other Fast IPS-based LCDs available today, so we are talking about a 1920×1080 resolution, 400 nits peak luminance, a 1000:1 contrast ratio, 178°/178° viewing angles, a 1 ms GtG response time (which can be reduced further to 0.1 ms – 0.5 ms response time with overdrive, depending on the model), and a 240 Hz maximum refresh rate with VESA’s Adaptive-Sync technology as well as NVIDIA’s G-Sync Compatible certification on top. The LCD can display 16.78 million of colors and can reproduce 99% of the sRGB color space, just like other monitors that use the same panels.
For connectivity, the new Acer Predators 240 Hz monitors have one DisplayPort 1.2a connector, two HDMI 2.0b inputs, and a quad-port USB 3.0 hub. On the audio side of things, the LCDs have 2W stereo speakers, and a headphone output.
Traditionally for Acer Predator monitors aimed at esports professionals and hardcore gamers, the displays come equipped with aggressively looking stands that can adjust height, tilt, and swivel. Also the LCDs can work in portrait mode.
| Acer’s Fast IPS Displays with a 240 Hz Refresh Rate | |||
| XB273GXbmiiprzx | XB253QGXbmiiprzx | ||
| Panel | 27-inch class IPS | 24.5-inch class IPS | |
| Native Resolution | 1920 × 1080 | ||
| Maximum Refresh Rate | 240 Hz | ||
| Dynamic Refresh | Technology | VESA Adaptive-Sync NVIDIA G-Sync Certified |
|
| Range | DP: 50 Hz – 240 Hz (?) HDMI: 56 Hz – 240 Hz (?) |
||
| Brightness | Standard: 350 cd/m² HDR: 400 cd/m² |
Standard: 400 cd/m² HDR: 400 cd/m² |
|
| Contrast | 1000:1 | ||
| Viewing Angles | 178°/178° horizontal/vertical | ||
| Response Time | 1 ms GtG OD: 0.1 ms |
1 ms GtG OD: 0.5 ms |
|
| Pixel Pitch | ~0.3113 mm² | ~0.2825 mm² | |
| Pixel Density | ~82 PPI | ~90 PPI | |
| Color Gamut Support | 99% sRGB | ||
| Inputs | 1×DP 1.2a 2×HDMI 2.0b |
||
| Audio | audio output | ||
| USB | 4-port USB 3.0 hub | ||
| Stand | Height: +/- 115 mm Tilt: 5° to 20° Swivel: 20° to 20° Pivot: 90° to 90°
|
Height: +/- 115 mm Tilt: 5° to 25° Swivel: 20° to 20° Pivot: 90° to 90°
|
|
| Warranty | 3 years | ||
| MSRP | ? | ? | |
So far, only Acer Japan has introduced the company’s first 240 Hz Fast IPS Predator-branded displays with a plan to start selling them as early as this week, but we are not sure about intentions of Acer’s divisions from other countries. The smaller 24.5-inch Predator XB253QGXbmiiprzx is expected to be priced at ¥46,000 (think about an MSRP of around $430 in the States), whereas the larger 27-inch Predator XB273GXbmiiprzx is projected to cost ¥55,000 (so, expect an MSRP of about $500 in the USA).
Related Reading:
- Acer Launches Predator XN253QX Monitor with 240 Hz & 0.4 ms G2G Response Time
- Gone in 240 Hz: Lenovo’ Legion Y25-25 ‘Fast IPS’ Monitor w/ FreeSync at CES 2020
- Quick & Deadly: Alienware 25 (AW2521HF) 240 Hz Fast IPS Monitor Revealed
- Supersonic: ViewSonic’s Elite XG270 240 Hz IPS Monitor w/ VRR & HDR
- Need for Speed: The LG UltraGear (27GN750) 240 Hz IPS Monitor with G-Sync
- Fast & Furious: The Alienware 27 (AW2720HF) 240 Hz IPS Monitor with FreeSync
- Assassin’s Speed: Eve Technology Reveals 27-Inch QHD Monitors With 240Hz Variable Refresh
Source: AnandTech – Predators: Acer Launches 24.5 & 27-Inch Fast IPS 240 Hz Monitors