ASRock Industrial maintains a lineup of ultra-compact form-factor machines in the NUC BOX (Intel-based) and 4X4 BOX (AMD-based) series. These systems have gained significant market acceptance (evidenced by the rapid iterations that the company has been able to put out over multiple generations). Being the first to market with the latest platforms has been one of the key reasons behind this.
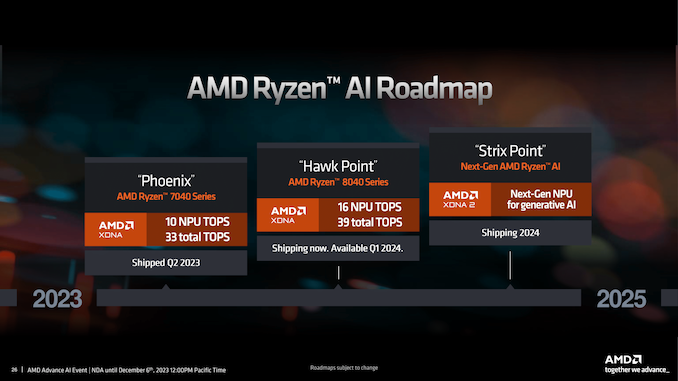
Both Intel and AMD have started to play up hardware-accelerated AI tasks as a key selling point in recent months. Intel has integrated support for NPUs (Neural Processing Unit – the accelerator for neural networks used in machine learning for the tech-savvy folks / artificial intelligence for the average consumer) in the recently-launched Meteor Lake SKUs. AMD’s Phoenix lineup of notebook chips launched earlier this year actually had NPU components on the die in some of the SKUs (AMD’s XDNA). This is now receiving more software support and marketing focus after getting re-branded as Ryzen AI in the recently-launched Phoenix refresh (8040 series APUs).
As is usual for ASRock Industrial, the company was quick to announce their UCFF machines based on both platforms within a few days of the Intel and AMD’s official launch. The 4X4 BOX 8040 Series launch was immediately followed by the introduction of the NUC(S) Ultra 100 BOX Series.
The rich I/O options from the previous generation of 4X4 BOX and NUC(S) BOX are retained as-is, but the key updates are related to the availability of a NPU in the internal platform. On the NUC(S) BOX side, Intel now provides two additional low-power efficiency cores on a separate die in the package. Similar to the previous generation products, the 4X4 BOX 8040 Series and NUC Ultra 100 BOX Series are the thick versions (49mm height). The NUCS Ultra 100 BOX is the 38mm slim version without the 2.5″ SATA drive support and the second LAN port. Each series has multiple processor options at different price points.
| ASRock Industrial’s AMD Hawk Point & Intel Meteor Lake UCFF PC Lineup | ||||
| Model | 4X4 BOX 8040 Series | NUC Ultra 100 BOX Series | NUCS Ultra 100 BOX Series | |
| CPU Options | AMD Ryzen 7 8840U 8C / 16T 3.3 GHz (Up to 5.1 GHz) 28W (4X4 BOX-8840U) AMD Ryzen 5 8640U 6C / 12T 3.5 GHz (Up to 4.9 GHz) 28W (4X4 BOX-8640U) |
Intel Core Ultra 7 155H (6P + 8E + 2e / 22T) 1.4GHz / 900MHz / 700MHz (up to 4.8GHz / 3.8 GHz / 2.5 GHz) 28W (NUC(S) BOX-155H) Intel Core Ultra 5 125H (4P + 8E + 2e / 22T) 1.2GHz / 700MHz / 700MHz (up to 4.5GHz / 3.6 GHz / 2.5 GHz) 28W (NUC(S) BOX-125H) |
||
| GPU | AMD Radeon 780M (12 CU / 768 Shaders) @ 2.7 GHz (4X4 BOX-8840U) AMD Radeon 760M (8 CU / 512 Shaders) @ 2.6 GHz (4X4 BOX-8640U) |
Intel Arc Xe 8 Cores @ 2.25 GHz (NUC(S) BOX-155H) Inte Arc Xe 7 Cores @ 2.2 GHz (NUC(S) BOX-125H) |
||
| NPU | Ryzen AI (up to 16 TOPS) | Intel AI Boost @ 1.4 GHz (up to 11 TOPS) | ||
| DRAM | Two DDR5 SO-DIMM slots Up to 96 GB of DDR5-5600 in dual-channel mode |
|||
| Motherboard | 10.4 cm x 10.2 cm x 3.6 cm (4.02″ x 4.09″) UCFF | |||
| Storage | SSD | 1x M.2-22(42/80) (PCIe 4.0 x4) 1x M.2-2242 (PCIe 4.0 x4) |
1x M.2-22(42/80) (PCIe 4.0 x4) 1x M.2-2242 (PCIe 4.0 x4) |
1x M.2-22(42/80) (PCIe 4.0 x4) 1x M.2-2242 (PCIe 4.0 x1) |
| DFF | – | 1 × SATA III Port (for 2.5″ drive) | – | |
| Wireless | Mediatek MT7922 (RZ616)? Wi-Fi 6E 2×2 802.11ax Wi-Fi (2.4Gbps) + Bluetooth 5.2 module |
Intel Wi-Fi 6E AX211 2×2 802.11ax Wi-Fi (2.4Gbps) + Bluetooth 5.3 module |
||
| Ethernet | 1x 2.5 GbE RJ-45 (Realtek RTL8125) 1x GbE RJ-45 (Realtek RTL8111H) |
1x 2.5 GbE RJ-45 (Intel I226-LM) 1x 2.5 GbE RJ-45 (Intel I226-V) |
1x 2.5 GbE RJ-45 (Intel I226-LM) | |
| USB | Front | 1× USB 3.2 Gen 2 Type-A 2x USB4 (with DisplayPort 1.4a) |
2× USB 3.2 Gen 2 Type-A 1x USB4 / Thunderbolt 4 (with DisplayPort 2.1) 1x USB 3.2 Gen 2 Type-C (with DisplayPort 1.4a Alt Mode) |
|
| Rear | 2 × USB 2.0 Type-A | 2 × USB 3.2 Gen 2 Type-A | ||
| Display Outputs | 2 × HDMI 2.1 (Rear, up to 8Kp60) 2 × DisplayPort 1.4a (using Front Panel Type-C ports, up to 4Kp60) |
2 × HDMI 2.1 (Rear, up to 4Kp60) 1 × DisplayPort 1.4a (using Front Panel Type-C port, up to 4Kp60) 1 × DisplayPort 2.1 (using Front Panel Type-C port, up to 4Kp60) |
||
| Audio | 1 × 3.5mm audio jack (Realtek ALC256) | |||
| PSU | External (19V/120W) (4X4 BOX-8840U) External (19V/90W) (4X4 BOX-8640U) |
External (19V/120W) (NUC(S) BOX-155H) External (19V/90W) (NUC(S) BOX-125H) |
||
| Dimensions | Length: 117.5 mm Width: 110 mm Height: 49 mm |
Length: 117.5 mm Width: 110 mm Height: 38 mm |
||
| Product Links | 4X4 BOX-8040 Series | NUC BOX-100 Series | NUCS BOX-100 Series | |
Note that the M.2 2280 support is enabled by a separate bracket, similar to the previous generation UCFF systems from the company. The Intel platform’s WLAN module seems to have received a slight upgrade from the AX210 to the AX211, which brings in Bluetooth 5.3 support. There is still no sign of Wi-Fi 7 / 802.11be support, but the industry is probably waiting for notebook makers to take the lead. In any case, for industrial PCs, the wired LAN subsystem is more important than the wireless one. The dual RJ-45 ports in most of the new models is a welcome trend from that viewpoint.

4X4 BOX-8040 Series I/O
The word on the street right now is that the Arc Xe Graphics in Meteor Lake brings Intel on a competitive footing against the RDNA3-based Radeon 780M in the Phoenix parts. The AI performance claims are more of a mixed bag, because Intel has been pushing a hybrid strategy that includes all of the CPU, GPU, and NPU in accelerating machine learning tasks. AMD’s approach for client platforms is not clear yet beyond the promotion of the new NPU components on the die. Both companies claim to have significant support from software vendors, and that is good news for consumers.

NUC Ultra 100-BOX Series I/O

NUCS Ultra 100-BOX Series I/O
As ASRock Industrial re-uses the case designs and thermal solutions from previous generations for rapid iterations, it takes a few releases before customer feedback gets adopted. The glossy chassis is finally gone from all versions of the products, with the matte design seen in the NUCS BOX-1300 series making its way across the board. We are still worried about the lack of an effective thermal solution for the M.2 NVMe SSDs inside these systems. It remains to be seen in hands-on evaluation if any progress has been made on that front. The other aspect is that the BIOS is usually not power-optimized at launch, but we have seen the company release regular updates even for previous generation products in an effort to address that. Other than these minor nit-picks, the NUC(S) BOX and 4X4 BOX systems from ASRock Industrial have proved to be worthy replacements for the mainstream Intel NUCs. We have reached out to ASRock Industrial for clarity on market availability dates and pricing, and will update the article with the details after receiving them.
Source: ASRock Industrial – 4X4 BOX-8040 Series PR
Source: AnandTech – ASRock Industrial 4X4 BOX 8040 and NUC(S) Ultra 100 BOX Series Bring Accelerated AI to Mini-PCs