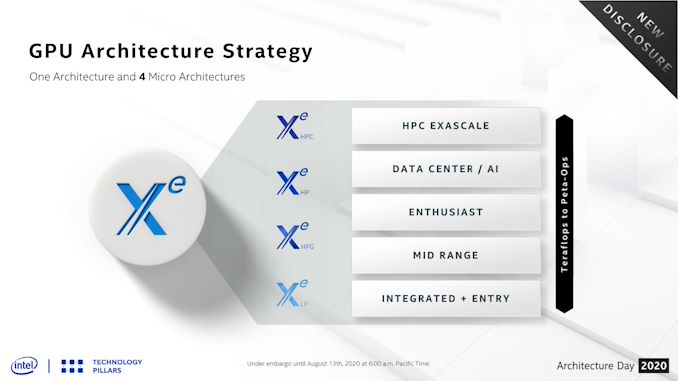
Among the many announcements in today’s Intel Architecture Day, Intel is also offering a major update to their GPU roadmap over the next 24 months. The Xe family, already jam-packed with Xe-LP, Xe-HP, and Xe-HPC parts, is now getting a fourth planned variant: Xe-HPG. Aimed directly at the enthusiast gamer market, this latest Xe variant will be Intel’s most gaming-focused part yet, and the biggest step yet in Intel’s plans to be more diversified in its foundry sources.
So what is Xe-HPG? At a high level, it’s meant to be the missing piece of the puzzle in Intel’s product stack, offering a high-performance gaming and graphics-focused chip. This is as opposed to Xe-HP, which is specializing in datacenter features like FP64 and multi-tile scalability, and Xe-HPC which is even more esoteric. In that respect, Xe-HPG can be thought of as everything in the Xe family, distilled down into a single design to push FLOPs, rays, pixels, and everything else a powerful video card might need.
Like with the rest of Intel’s forward-looking Xe announcements, the company isn’t offering performance projections, features, or the like. But we do have some small details on what to expect.
First and foremost, beyond going after the enthusiast performance space, Intel has confirmed that this part will support ray tracing. A marquee feature of high-end video cards, ray tracing will take on even greater important over the coming years as the soon-to-launch next-generation consoles head out the door with the feature as well, eventually transforming it into a baseline feature across all gaming platforms. Similarly, ray tracing is a critical component of Microsoft’s DirectX 12 Ultimate standard, which given the timing of this GPU and Intel’s intentions, I would be shocked if Intel didn’t support in full.

The chip will be built on the foundation that is Xe-LP. However it will also pull in technologies that Intel is pioneering for Xe-HP, and Xe-HPC. Not the least of which is raw scalability, which is being able to take the Xe-LP foundation and scale it up to hundreds (if not thousands) of GPU execution units. But Intel is also pulling what they are calling “compute frequency enhancements” from Xe-HPC, which presumably will allow them to maximize the chip’s overall clockspeeds. All told, I won’t be too surprised if it looks a lot like Xe-HP in general, except with server-driven features like fast FP64 support and multi-tiling stripped out.
But Xe-HPG will also bring something new to the table for the entire Xe family: GDDR6 support. Intel is confirming that the chip – or rather, the microarchitecture the chip will be based on – will be designed to work with GDRR6. This is as opposed to Xe-HP(C), which as high-end server parts use HBM, and Xe-LP, which is designed for use with more conventional memory types. GDDR6 compatibility is a unique need that reflects this is a gaming focused part: GDDR6 provides the memory bandwidth needed for high-performance graphics, but without the stratospheric costs of HBM memory (a problem that has impacted some other high-end GPUs over the years). In a further twist, Intel apparently licensed the GDDR controller IP from outside the company, rather than developing it in-house; so Xe-HPG will have a very notable bit of external IP in it.

But perhaps most interesting of all for graphics insiders and Intel investors alike is where Xe-HPG will be built: not at Intel. As part of their Architecture Day roadmap, Intel has confirmed that the part will be made at an external fab. In fact it’s the only Xe part where the GPU (or at least the compute element) is being made entirely at a third-party fab. Intel of course will not reveal which fab this is – if it’s TSMC or Samsung – but it means we’re going to see a complete Intel GPU built at another fab. If nothing else, this is going to make comparing Xe-HPG to its AMD and NVIDIA rivals a lot easier, since Intel will be using the same fab resources.
Looking at the same roadmap, it’s worth pointing out that Intel won’t be using any of their advanced packaging technologies for the part. Since they’re not using HBM and they’re not doing multi-tiling, there’s no need for things like EMIB, never mind Foveros. There’s still a lot of unknowns with the cost aspects of Intel’s advanced packaging technologies, so keeping it out of Xe-HPG will presumably help keep costs in check in a very competitive marketplace.
And that is the scoop on Xe-HPG. The latest and most gaming-focused member of Intel’s Xe GPU product stack is set to launch in 2021 – and as Intel looks to break into the wider GPU market, I don’t doubt for a second that this won’t be the last we’ll hear of it between then and now.
![]()
![]()
Source: AnandTech – Intel’s Xe-HPG GPU Unveiled: Built for Enthusiast Gamers, Built at a Third-Party Fab