More RAM is a handy script that sets up ZRAM to increase the capacity of your RAM. ZRAM is a kernel module to compress data on-the-fly and store it in RAM. It has all sorts of uses, and works well with the Pi.
Writeback for filesystems is the process of flushing the “dirty” (written)
data in the page cache to storage. At
the 2025 Linux Storage,
Filesystem, Memory Management, and BPF Summit (LSFMM+BPF), Anuj Gupta led a
combined storage and filesystem session on some work that has been done
to parallelize the writeback process. Some of the performance problems
that have been seen with the existing single-threaded writeback came up in
a session at last year’s summit, where the
idea of doing writeback in parallel was discussed.
Granting passwordless root privileges can streamline workflows, especially when managing multiple automated processes or scripts that require administrative access. If you’re already familiar with changing a user’s default shell, the next step in managing user permissions effectively is understanding how to safely give sudo access without a password prompt.
Rocky Linux 10 has been released today as a free alternative to the Red Hat Enterprise Linux 10 operating system series, adding various major changes both from upstream and in-house.
As data and data-driven technologies become a bigger part of everyday life, it’s more important than ever to make sure that young people are given the chance to learn data science concepts and skills.
David WeintropRotem Israel-FishelsonPeter F Moon
In our April research seminar, David Weintrop, Rotem Israel-Fishelson, and Peter Moon from the University of Maryland introduced API Can Code, a data science curriculum designed with high school students for high school students. Their talk explored how their innovative work uses real-world data and students’ own experiences and interests to create meaningful, authentic learning experiences in data science.
Quick note for educators: Are you interested in joining our free, exploratory data science education workshop for teachers on 10 July 2025 in Cambridge, UK? Then find out the details here.
David started by explaining the motivation behind the API Can Code project. The team’s goal was not to turn students into future data scientists, but to offer students the data literacy they need to explore and critically engage with a data-driven world.
The work was also guided by a shared view among leading teachers’ organisations that data science should be taught across all subjects in the K–12 curriculum. It also draws on strong research showing that when educational experiences connect with students’ own lives and interests, it leads to deeper engagement and better learning outcomes.
Reviewing the landscape
To prepare for the design of the curriculum, David, Rotem, and Peter wanted to understand what data science education options already exist for K–12 students. Rotem described how they compared four major K–12 data science curricula and examined different aspects, such as the topics they covered and the datasets they used. Their findings showed that many datasets were quite small in size, and that the datasets used were not always about topics that students were interested in.
The team also looked at 30 data science tools used across different K–12 platforms and analysed what each could do. They found that tools varied in how effective they were and that many lacked accessibility features to support students with diverse learning needs.
This analysis helped to refine the team’s objective: to create a data science curriculum that students find interesting and that is informed by their values and voices.
Participatory design
To work towards this goal, the team used a methodology called participatory design. This is an approach that actively involves the end users — in this case, high school students — in the design process. During several in-person sessions with 28 students aged 15 to 18 years old, the researchers facilitated low-tech, hands-on activities exploring the students’ identities and interests and how they think about data.
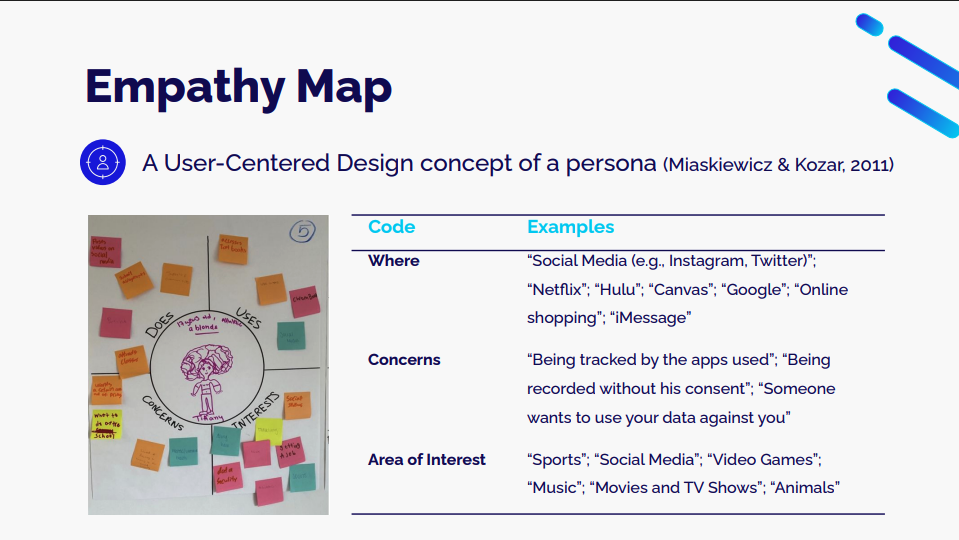
One activity, Empathy Map, involved students working together to create a persona representing a student in their school. They were asked to describe the persona’s daily life, interests, and concerns about technology and data:
The students’ involvement in the design process gave the team a better understanding of young people’s views and interests, which helped create the design of the API Can Code curriculum.
API Can Code: three units, three key tools
Peter provided an overview of the API Can Code curriculum. It follows a three-unit flow covering different concepts and tools in each unit:
Unit 1 introduces students to different types of data and data science terminology. The unit explores the role of data in the students’ daily lives, how use and misuse of data can affect them, different ways of collecting and presenting data, and how to evaluate databases for aspects such as size, recency, and trustworthiness. It also introduces them to RapidAPI, a hub that connects to a wide range of APIs from different providers, allowing students to access real-world data such as Zillow housing prices or Spotify music data.
Unit 2 covers the computing skills used in data science, including the use of programming tools to run efficient data science techniques. Students learn to use EduBlocks, a block-based programming environment where students can draw in JSON files from RapidAPI datasets, and process and filter data without needing a lot of text-based programming skills. The students also compare this approach with manual data processing, which they discover is very slow.
Unit 3 focuses on data analysis, visualisation, and interpretation. Students use CODAP, a web-based interactive data science tool, to calculate summary statistics, create graphs, and perform analyses. CODAP is a user-friendly but powerful platform, making it perfect for students to analyse and visualise their data sets. Students also practise interpreting pre-made graphs and the graphs and statistics that they are creating.
Peter described an example activity carried out by the students, showing how these three units flow together and build both technical skills and an understanding of the real-world uses of data science. Students were tasked with analysing a dataset from Zillow, a property website, to explore the question “How much does a house in my neighbourhood cost?” The images below show the process the students followed, which uses the data science skills and tools from all three units of the curriculum.
Click on an image to enlarge it.
Interest-driven learning in action
A central tenet of API Can Code is that students should explore data that matters to them. A diverse range of student interests was identified during the design work, and the curriculum uses these areas of interest, such as music, movies, sports, and animals, throughout the lessons.
The curriculum also features an open-ended final project, where students can choose a research question that is important to them and their lives, and answer it using data science skills.
The team shared two examples of memorable final projects. In one, a student set out to answer the question “Is Jhené Aiko a star?” The student found a publicly available dataset through an API provided by Deezer, a music streaming platform. She wrote a program that retrieved data on the artist’s longevity and collaborations, analysed the data, and concluded that Aiko is indeed a star. What stood out about this project wasn’t just the fact that the student independently defined stardom and answered their research question using real data, but that this was a truly personal, interest-driven project. David noted that the researchers could never have come up with this activity, since they had never previously heard of Jhené Aiko!
Jhené Aiko, an R&B singer-songwriter (Photo by Charito Yap, licensed under CC BY-ND 2.0)
Another student’s project analysed data about housing in Washington DC to answer the question “Which ward in DC has the most affordable houses?” Rotem explained that this student was motivated by her family thinking about moving away from the city. She wanted to use her project to persuade her parents to stay by identifying the most affordable ward in DC that they could move to. She was excited by the outcome of her project, and she presented her findings to other students and her parents.
These projects underscore the power of personally important data science projects driven by students’ interests. When students care about the questions they are exploring, they’re more invested in the process and more likely to keep using the skills and concepts they learn.
Resources
API Can Code is available online and completely free to use. Teachers can access lesson plans, tutorial videos, assessment rubrics, and more from the curriculum’s website https://apicancode.umd.edu/. The site also provides resources to support students, including example programs and glossaries.
Join our next seminar
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our next seminar on Tuesday, 17 June from 17:00 to 18:30 BST to hear Netta Iivari (University of Oulu) introduce transformative agency and its importance for children’s computing education in the age of AI.
To sign up and take part in our research seminars, click below:
Back in April I published Linux benchmarks of the Lenovo ThinkPad T14s Gen 6 with the AMD Ryzen AI 7 PRO 360 SoC. Some follow-up benchmarks I did back then that I have been meaning to publish is looking at the ACPI Platform Profile impact on performance and power for this ThinkPad laptop under Linux. Here are those numbers…
Ubuntu has long stood as a bastion of accessibility, polish, and power in the Linux ecosystem. With the arrival of Ubuntu 25.04, codenamed “Plucky Puffin”, Canonical has once again demonstrated its commitment to delivering a modern, forward-thinking operating system. This release isn’t just a routine update — it’s a confident stride into a future where Linux desktops are visually stunning, developer-friendly, and brimming with potential.
This article dives into what makes Pop!_OS 24.04 a game-changer, focusing especially on its sophisticated, yet user-friendly approach to hybrid graphics.
PCI Express 7.0 was announced back in 2022 as coming in 2025 with 128 GT/s Since then draft specifications were published while today PCI-SIG is announcing the formal PCI Express 7.0 specification release along with a new PCIe Optical Interconnect Solution…
The popular open-source audio editing software Audacity has just released version 3.7.4, a patch update that squashes bugs and smooths out the user experience.
DAMON is a nifty data access monitoring solution for the Linux kernel developed by Amazon and other parties for system monitoring and performance/efficiency optimizations and more. But it’s not so ground-breaking that it’s worth enabling by default in all Linux kernel builds, Linus Torvalds has decided…
The Ultra Ethernet Consortium today published the UEC Specification 1.0 release. Nearly two years ago the Ultra Ethernet Consortium was started by Intel, AMD, Meta, HPE, and others and hosted by the Linux Foundation for open and high performance networking with an emphasis on AI and HPC…
Cybercriminals are now leveraging AI-generated content on TikTok to spread malware and deceive users at scale. According to a recent report by GBHackers, attackers are using highly convincing deepfake-style videos—many of them created with generative AI—to promote fake apps, phishing links, and malicious downloads. The campaign is part of a growing trend where social media is weaponized to deliver advanced threats that traditional security tools often fail to detect.
A recently disclosed set of Linux kernel vulnerabilities has put system administrators and Linux users on high alert. As reported by The Hacker News, these flaws allow attackers to potentially leak sensitive data from kernel memory, including password hashes and encryption keys. This development follows closely after major updates in the Linux world—like the release of AlmaLinux OS 10—and comes amid rising concerns around other critical threats, such as the ongoing Chrome zero-day affecting Windows and Linux.
DragonFlyBSD has updated its Direct Rendering Manager (DRM) kernel graphics/display driver code that it ports over from what’s available in the upstream Linux kernel. The latest revision to the DragonFlyBSD kernel graphics driver code enables support for some new hardware platforms but remains woefully behind the latest generation dGPUs/iGPUs and what is found in the upstream Linux kernel…
DXVK 2.6.2 Vulkan-based implementation of D3D9, D3D10, and D3D11 for Linux / Wine is now available for download with improvements for several games and various bug fixes.