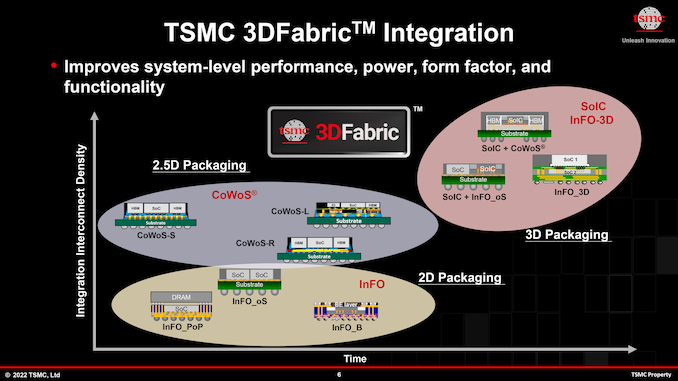
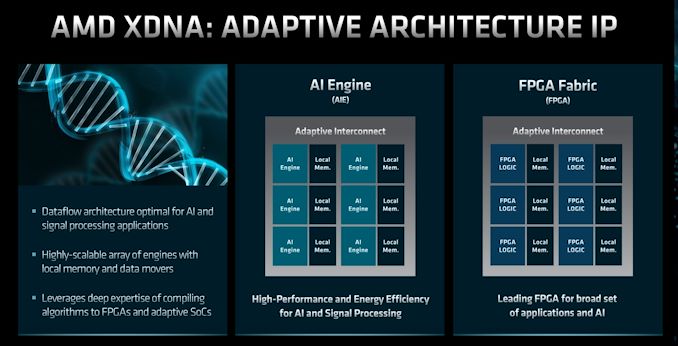
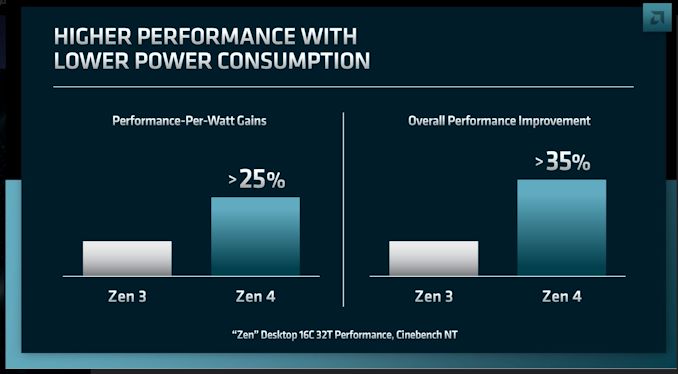
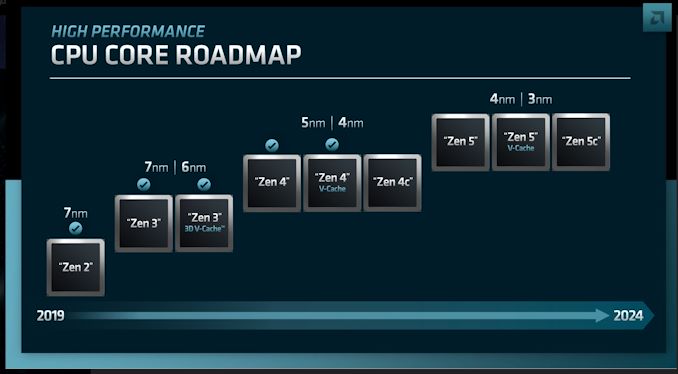
Taiwan Semiconductor Manufacturing Co. on Thursday kicked off its 2022 TSMC Technology Symposium, where the company traditionally shares it process technology roadmaps as well as its future expansion plans. One of the key things that TSMC is announcing today are its leading-edge nodes that belong to its N3 (3 nm class) and N2 (2nm class) families that will be used to make advanced CPUs, GPUs, and SoCs in the coming years.
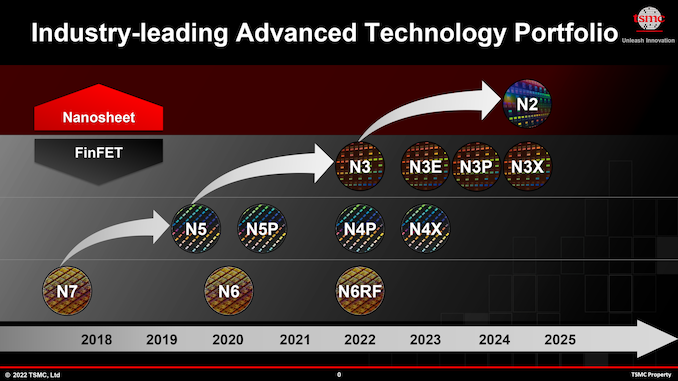
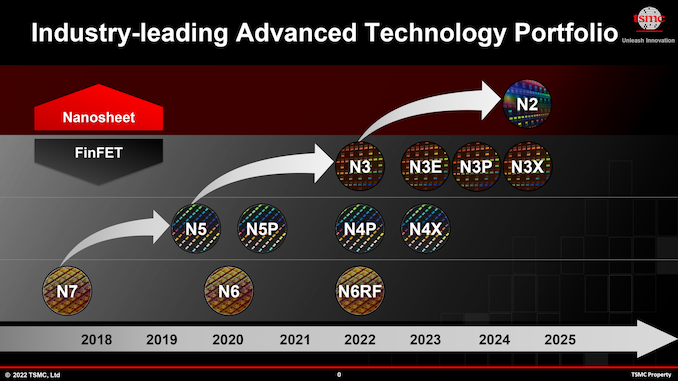
N3: Five Nodes Over Next Three Years
As fabrication processes get more complex, their pathfinding, research, and development times get stretched out as well, so we no longer see a brand-new node emerging every two years from TSMC and other foundries. With N3, TSMC’s new node introduction cadence is going to expand to around 2.5 years, whereas with N2, it will stretch to around three years.
This means that TSMC will need to offer enhanced versions of N3 in order to meet the needs of its customers who are still looking for a performance per watt improvement as well as transistor density bump every year or so. Another reason why TSMC and its customers need multiple versions of N3 is because the foundry’s N2 relies on all-new gate-all-around field-effect transistors (GAA FETs) implemented using nanosheets, which is expected to come with higher costs, new design methodologies, new IP, and many other changes. While developers of bleeding-edge chips will be quick to jump to N2, many of TSMC’s more rank & file customers will stick to various N3 technologies for years to come.
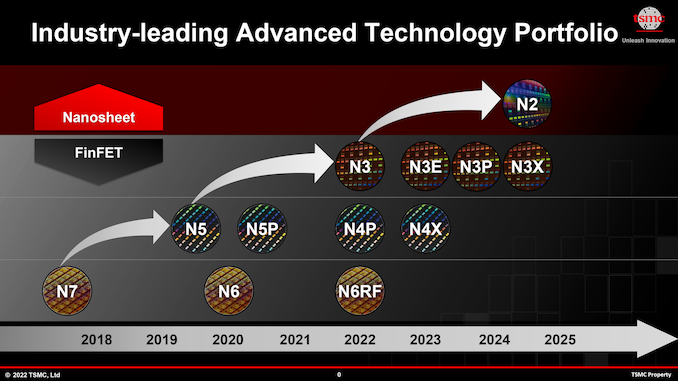
At its TSMC Technology Symposium 2022, the foundry talked about four N3-derived fabrication processes (for a total of five 3 nm-class nodes) — N3E, N3P, N3S, and N3X — set to be introduced over the coming years. These N3 variants are slated to deliver improved process windows, higher performance, increased transistor densities, and augmented voltages for ultra-high-performance applications. All these technologies will support FinFlex, a TSMC “secret sauce” feature that greatly enhances their design flexibility and allows chip designers to precisely optimize performance, power consumption, and costs.
Advertised PPA Improvements of New Process Technologies
Data announced during conference calls, events, press briefings and press releases |
| |
TSMC |
N4
vs
N5 |
N4P
vs
N5 |
N4P
vs
N4 |
N4X
vs
N5 |
N4X
vs
N4P |
N3
vs
N5 |
N3E
vs
N5 |
| Power |
lower |
-22% |
– |
? |
? |
-25-30% |
-34% |
| Performance |
higher |
+11% |
+6% |
+15%
or
more |
+4%
or more |
+10-15% |
+18% |
Logic Area
Reduction* %
Logic Density* |
0.94x
-6%
1.06x |
0.94x
-6%
1.06x |
– |
? |
? |
0.58x
-42%
1.7x |
0.625x
-37.5%
1.6x |
Volume
Manufacturing |
2022 |
2023 |
H2 2022 |
2023 |
2023 |
H2 2022 |
Q2/Q3 2023 |
*Note that TSMC only started to publish transistor density enhancements for analog, logic, and SRAM separately around 2020. Some of the numbers still reflect ‘mixed’ density consisting of 50% logic, 30% SRAM, and 20% analog.
N3 and N3E: On Track for HVM
TSMC’s first 3 nm-class node is called N3 and this one is on track to start high volume manufacturing (HVM) in the second half of this year. Actual chips are set to be delivered to customers in early 2023.This technology is mostly aimed at early adopters (read: Apple and the like) who can invest in leading-edge designs and would benefit from the performance, power, area (PPA) advantages offered by leading-edge nodes. But as it’s tailored for particular types of applications, N3 has a relatively narrow process window (a range of parameters that produce a defined result), which may not be suitable for all applications in terms of yields.
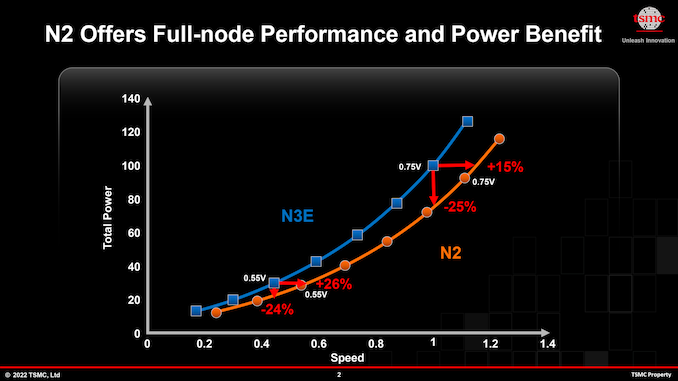
This is when N3E comes into play. The new technology enhances performance, lowers power, and increases the process window, which results in higher yields. But the trade-off is that the node features a slightly reduced logic density. When compared to N5, N3E will offer a 34% reduction in power consumption (at the same speed and complexity) or an 18% performance improvement (at the same power and complexity), and will increase logic transistor density by 1.6x.
It is noteworthy that, based on data from TSMC, N3E will offer higher clockspeeds than even N4X (due in 2023). However the latter will also support ultra-high drive currents and voltages of above 1.2V, at which point it will be able to offer unbeatable performance, but with very high power consumption.
In general, N3E looks to be a more versatile node than N3, which is why it is not surprising that TSMC has more ‘3nm tape outs’ at this point than it had with its 5 nm-class node at a similar point of its development.
Risk production of chips using N3E is set to start in the coming weeks (i.e., in Q2 or Q3 2022) with HVM set for mid-2023 (again, TSMC does not disclose whether we are talking about Q2 or Q3). So expect commercial N3E chips to be available in late 2023 or early 2024.
N3P, N3S, and N3X: Performance, Density, Voltages
N3’s improvements do not stop with N3E. TSMC is set to bring out N3P, a performance-enhanced version of its fabrication process, as well as N3S, density-enhancing flavor of this node, some time around 2024. Unfortunately, TSMC is not currently disclosing what improvements these variants will offer compared to baseline N3. In fact, at this point TSMC does not even show N3S in all versions of its roadmap, so it is really not a good business to try guessing its characteristics.
Finally, for those customers who need ultra-high performance no matter power consumption and costs, TSMC will offer N3X, which is essentially an ideological successor of N4X. Again, TSMC is not revealing details about this node other than that it will support high drive currents and voltages. We might speculate that N4X could use backside power delivery, but since we are talking about a FinFET-based node and TSMC only going to implement backside power rail in GAAFET-based N2, we are not sure this is the case. Nonetheless, TSMC probably has a number of aces up its sleeve when it comes to voltage increases and performance enhancements.
FinFlex: N3’s Secret Sauce
Speaking of enhancements, we should definitely mention TSMC’s secret sauce for N3: FinFlex technology. In short, FinFlex allows chip designers to precisely tailor their building blocks for higher performance, higher density, and lower power.
When using a FinFET-based node, chip designers can choose between different libraries using different transistors. When developers need to minimize die size and save power at the cost of performance, they use double-gate single-fin (2-1) FinFETs (see the illustration). But when they need to maximize performance at the trade-off of die size and higher power, they use triple-gate dual-fin (3-2) transistors. When developers need a balance, they go with dual-gate dual-fin (2-2) FinFETs.

Currently, chip designers have to stick to one library/transistor type either for the whole chip or the whole block in a SoC design. For example, CPU cores can be implemented using 3-2 FinFETs to make them run faster, or 2-1 FinFETs to reduce their power consumption and footprint. This is a fair tradeoff, but it’s not ideal for all cases, especially when we are talking about 3 nm-class nodes that will be more expensive to use than existing technologies.
For N3, TSMC’s FinFlex technology will allow chip designers to mix and match different kinds of FinFETs within one block to precisely tailor performance, power consumption, and area. For complex structures like CPU cores, such optimizations give a lot of opportunities to increase core performance while still optimizing die sizes. So, we are eager to see how SoC designers will be able to take advantage of FinFlex in the looming N3 era.
FinFlex is not a substitute for node specialization (performance, density, voltages) as process technologies have greater differences than the ibraries or transistor structures within a single process technology, but FinFlex looks to be a good way to optimize performance, power, and costs for TSMC’s N3 node. Ultimately, this technology will bring the flexibility of FinFETs a little closer to that of GAAFETs, which are slated to offer adjustable channel widths to get higher performance or reduce power consumption.
Summary
Like TSMC’s N7 and N5, N3 will be another family of long-lasting nodes for the world’s largest contrast maker of semiconductors. Especially with the jump to GAAFETs coming up at 2nm for TSMC, the 3nm family will be the final family of “classic” leading-edge FinFET nodes from the firm, and one that a lot of customers will stick to for several years (or more). Which, in turn, is why TSMC is prepping multiple versions of N3 tailored for different applications – as well as FinFlex technology to give chip designers some additional flexibility with their designs.
The first N3 chips are set to enter production in the coming months and arrive to the market in early 2023. Meanwhile, TSMC will keep producing semiconductors using its N3 nodes long after it introduces its N2 process technology in 2025.
Source: AnandTech – TSMC Readies Five 3nm Process Technologies, Adds FinFlex For Design Flexibility